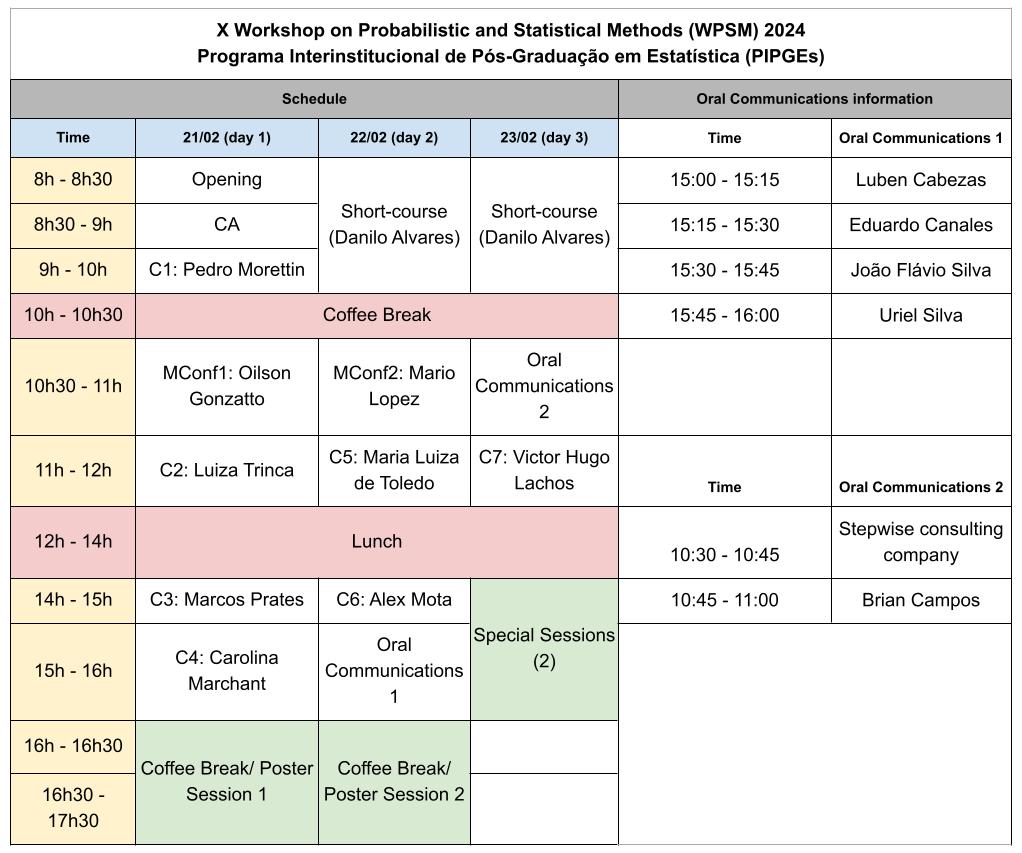
X Workshop on Probabilistic and Statistical Methods
February 21-23, 2024
X Workshop on Probabilistic and Statistical Methods
February 21-23, 2024
The Workshop on Probabilistic and Statistical Methods (WPSM) is a meeting organized by the Joint Graduate Program in Statistics UFSCar/USP (PIPGEs, São Carlos, SP, Brazil) with the aim of discussing new developments in Probability, Statistics, and their applications.
Activities include 7 plenary conferences and 2 mini-conferences with national and international
researchers and one short-course. Two special sessions are also scheduled on Recent Advances in
Reliability Systems and Probability and Mathematical Statistics, 2 poster sessions and 2 oral
communication sessions.
Pedro Morettin - IME (São Paulo)
In this talk I will consider the connections between time series and some techniques of Machine Learning, namely clustering, prediction and classification. Special neural networks like LSTM and convolutional networks will be briefly described and applications will be Illustrated.
Luzia Aparecida Trinca - UNESP (Botucatu)
Many research areas (laboratory biology, agriculture, engineering and others) develop by performing complex experimentation. Often, the experiments involve several factors and are subject to restrictions on the randomization process and the amount of resources available. Randomization restrictions lead to multi-stratum experiments that can exhibit nested or crossed layouts and, sometimes, both structures. Ideal orthogonal designs do not exist under these tight conditions, and optimum design methods play an important role, allowing the construction of efficient designs for the practical problem at hand. However, an optimum design is highly dependent on both the optimality criteria and the a priori model assumed for the analysis. Recent developments consider compound criteria involving several desired properties, including a few potential models to construct designs, while more robust but with high efficiency concerning the desired properties. In this talk, we will discuss compound design criteria and present a method for design construction and several illustrations based on practical problems.
Marcos Oliveira Prates - UFMG (Belo Horizonte)
Accurately modeling spatial dependence is crucial for analyzing areal data, affecting both parameter estimation and outcome prediction. While adjacency matrices are commonly used to model spatial dependence, this approach fails to distinguish between polygons of different sizes and shapes and may struggle with spatial misalignment and data fusion. To address these challenges, we propose the Hausdorff-Gaussian process (HGP), a general class of models that uses the Hausdorff distance to model spatial dependence in both point and areal data. The HGP can accommodate various modeling techniques, including geostatistical and areal models, within a single unified framework. Moreover, the HGP can be integrated into generalized linear mixed-effects models, making it valuable for addressing change of support and data fusion. We demonstrate the effectiveness of the HGP by applying it to a respiratory cancer dataset in Great Glasgow and comparing it to popular areal models. We show that the HGP outperforms these models, indicating its superior performance in modeling areal data. Additionally, we illustrate the versatility of the HGP by applying it to a precipitation data fusion dataset in Switzerland. Overall, the HGP provides a flexible and robust approach for modeling spatial data of different types and shapes, with potential applications in diverse fields such as public health and climate science.This work was supported by CAPES, CNPq and FAPEMIG. This is a joint work with Lucas Godoy and Jun Yan.
Carolina Marchant - Universidad de Talca (Chile)
Increasing levels of air pollution worldwide have caused a variety of adverse effects on the health of the human population. According to a recent study from the World Health Organization, nine out of every ten people on the planet breathe air that contains high levels of pollutants and seven million people die every year due to this cause. This problem is also perceived in several cities of Chile. According to World Air Quality Index Ranking, which measure the air quality index based on the levels of ?ne particles, Chile currently ranks second, following Peru, in terms of cities with the highest levels of?ne particulate matter of Latin America and the Caribbean (https://www.iqair.com/world-air-quality-ranking). Then, the evidence points to a serious public health problem in Chile, due to the high levels of particulate matter available in the air, in particular in the winter period. In this context, we present predictive models developed by us to model levels of particulate matter in function of climatological and meteorological variables. Specifically, we present semi-parametric and machine learning models. We apply these models to real air pollution data, climatological and meteorological variables in Chilean cities using R-project software. This application shown that the proposed models are useful for alerting episodes of extreme urban environmental pollution, allowing us to prevent adverse effects on human health for the Chilean population.
Maria Luiza Guerra de Toledo - ENCE (Rio de Janeiro)
No cenário industrial, compreender o processo de falhas de sistemas reparáveis é essencial para se desenhar estratégias de manutenção eficientes. Uma política de manutenção adequadamente implementada ajuda a reduzir o risco de falhas, e, portanto, de despesas não-planejadas e condições inseguras. Sistemas de engenharia atuais abarcam um nível alto de tecnologia que os permitem gerar dados em tempo real (big data). Tais dados podem ser tanto registros de condições de operação do sistema, quanto condições ambientais, e usualmente fornecem informações substanciais para embasar a análise de confiabilidade desses sistemas. Este trabalho apresenta uma discussão sobre as oportunidades e desafios da interação entre big data e confiabilidade. É apresentada uma revisão do desenvolvimento recente nessa direção, e uma discussão sobre como métodos analíticos podem ser desenvolvidos para monitorar os aspectos desafiadores que surgem das características complexas do uso de big data em aplicações de confiabilidade. Além disso, discute como vincular dados de operação de sistemas e dados ambientais com respostas tradicionais de confiabilidade, tais como tempo até a falha, tempo de recorrência de eventos, e medidas de degradação. Em particular, utiliza uma abordagem de aprendizado de máquina supervisionada para predizer a confiabilidade em componentes industriais, utilizando-se uma base de dados real de falhas em um sistema industrial.
Alex Leal Mota - UFAM (Manaus)
In this work, we propose a new cure rate frailty regression model based on a two-parameter weighted Lindley distribution. The weighted Lindley distribution has attractive properties such as flexibility on its probability density function, Laplace transform function on closed-form, among others. An advantage of proposed model is the possibility to jointly model the heterogeneity among patients by their frailties and the presence of a cured fraction of them. To make the model parameters identifiable, we consider a reparameterized version of the weighted Lindley distribution with unit mean as frailty distribution. The proposed model is very flexible in sense that has some traditional cure rate models as special cases. The statistical inference for the model?s parameters is discussed in detail using the maximum likelihood estimation under random right-censoring. Further, we present a Monte Carlo simulation study to verify the maximum likelihood estimators behavior assuming different sample sizes and censoring proportions. Finally, the new model describes the lifetime of 22,148 patients with stomach cancer, obtained from the Fundação Oncocentro de São Paulo, Brazil.
Victor Hugo Lachos Davila - University of Connecticut (EUA)
Matrix-variate distributions have proven to be useful for modeling three-way data. However, observations in this kind of data can be missing or subject to some upper and/or lower detection limits because of the restriction of the experimental apparatus. We propose a novel matrix-variate normal distribution for interval-censored and missing data. We develop an analytically simple yet efficient. EM-type algorithm to conduct maximum likelihood estimation of the parameters. The algorithm has closed-form expressions at the E-step that rely on formulas for the mean and variance of the truncated multinormal distribution and can be computed using available software. Results obtained from the analysis of both simulated and real datasets are reported to demonstrate the effectiveness of the proposed method.
Oilson Alberto Gonzatto Junior - ICMC (São Carlos)
Durante a aceleração da pandemia de COVID-19 a busca por equipamentos de proteção individual se tornou descontrolada. Em resposta a essa situação, um esforço imediato foi empreendido para desenvolver um sistema especializado que, considerando o contexto pandêmico, fosse capaz de prever a demanda desses equipamentos nos hospitais. O sistema se baseia em um conjunto de modelagens estatísticas que incorpora dados históricos, protocolos de uso e dados epidemiológicos. Nomeado Safety-Stock, o sistema oferece previsões de consumo e outras informações como níveis de estoque de segurança, permitindo aos hospitais o planejamento para garantir a manutenção de suas atividades, reduzindo o risco de escassez individual e colaborando com a cooperação entre hospitais para maximizar a disponibilidade de equipamentos durante a pandemia.
Mario Estrada Lopez - Universidad Nacional da Colombia (Colombia)
Although it began more than 60 years ago, network reliability is an area of study that still has much room for further development. Evidence of component failure dependences and the critical role played by these networks after natural disasters make them an area that needs further analysis. Ice storms are natural disasters affecting power grids that have become more recurrent. They correspond to a climatic phenomenon where freezing precipitation and wind speed can severely damage the networks due to the accumulation of ice and the impact of wind. We consider a Power grid where transmission lines fail due to a combination effect of wind and freezing precipitation. We calibrate a Marshall-Olkin multivariate vector that models the transmission lines? lifetimes. After the multivariate model parameters are determined, an accurate reliability estimation is obtained using variance reduction methods. We applied the technique to study the reliability of the Chilean Power Grid in the regions of Nuble and Bio Bio against the occurrence of ice storms. Joint work with Javiera Barrera, Jorge Jenschke and Gerardo Rubino.
Eder Brito - IFG (Goiânia)
In this study, we introduce models for the failure times of repairable systems, which experience failures due to different and independent causes while being influenced by unobservable effects acting on their failure processes. Furthermore, we assume that imperfect repairs are performed after each failure event to restore the system to its standard operational condition. In this sense, the proposed model combines the concept of imperfect repairs with independent competing risks linked by unobserved heterogeneity, which is shared by the failure times of each system. In addition to presenting these novel models, the objective of this work is to develop classic inferential methodologies for estimating maximum likelihood parameters and obtaining reliability prediction functions for each system based on its failure history. Real world applications of these models are conducted, demonstrating their capacity to identify the effect of repairs related to the causes of failure and the presence or absence of unobserved heterogeneity. Therefore, this research addresses a relevant issue in the field of reliability because, in addition to presenting models that extend and generalize ones in the literature, it has potential practical applicability in diverse scenarios involving repairable systems.
Paulo Henrique Ferreira da Silva - UFBA (Salvador)
In this study, we seek to propose a model that allows us to evaluate the failure times of a single repairable system represented hierarchically, exposed to competing risks and under a minimal repair framework. Our study can be regarded as an extension of the research presented in Louzada et al. (2019), which comprises the representation of complex systems through a hierarchical structure in series and/or in parallel. For this, we deduce the general form of the model, as well as the likelihood function associated with it, to obtain reliable estimates for the parameters that index the model. In addition, we display the mechanism for generating random numbers based on the presented structure, which enables obtaining point and interval estimates (via parametric bootstrap) in a more convenient way for reliability curves at any level of the system hierarchy. We conduct an extensive Monte Carlo simulation study to evaluate the performance of the proposed maximum likelihood estimators and confidence intervals for the model parameters. Finally, we illustrate the applicability of our model and methods with applications that deal with the reliability modeling of a robotic unit still under development, resulting from a project carried out in partnership between Petrobras and other Brazilian research centers.
Maria Luiza Guerra de Toledo - ENCE (Rio de Janeiro)
Modelos de degradação utilizam dados referentes a alguma característica do produto que possa ser relacionada à sua confiabilidade, e que seja observada ao longo do tempo. Neste trabalho, utilizou-se uma abordagem para modelar a degradação que supõe que essa ação é um processo aleatório no tempo, cujas sucessivas mensurações representam observações de um processo estocástico. Com o objetivo de se estimar informações sobre o tempo de vida de rodas de locomotiva, aplicou-se o processo Wiener em dados de degradação do diâmetro das rodas. Sob tal processo, as dinâmicas estocásticas são c aracterizadas pelo movimento Browniano, e o tempo até a falha possui distribuição Normal inversa. Entre os resultados obtidos, estima-se que a distância média percorrida pelas rodas até a ocorrência de uma falha é aproximadamente 841.554 km, e que cerca de 10% delas terão falhado até a distância de 684.056 km. Além das estimativas pontuais sobre funções do tempo de vida, estimação intervalar foi realizada utilizando o método de reamostragem Jackknife.
Valdivino Vargas Júnior - UFG (Goiânia)
Podemos pensar um processo de ramificação, em sua versão básica, como um modelo onde cada partícula (ou indivíduo) gera partículas (ou indivíduos) do mesmo tipo e em número distribuído de acordo com uma variável aleatória inteira não-negativa (a mesma lei para toda partícula ou indivíduo). Este tipo de processo tem aplicação nas mais variadas áreas do conhecimento, incluindo desde problemas de crescimento populacional, estudo de reações em cadeia, transmissão de informação em rede etc. No processo de ramificação, a evolução do processo se dá em gerações. O tamanho de uma geração é dado pelo número de filhos da geração anterior. Dentro dessa dinâmica é de interesse saber condições para a extinção do processo, com base na lei de probabilidade que dá o número de partículas ( ou indivíduos) geradas a partir de uma determinada partícula (ou indivíduo). Aqui extinção é o evento onde não há mais partículas (ou indivíduos) a partir de uma dada geração. Nosso objetivo é falar sobre essas condições e apresentar resultados básicos da teoria. Vamos falar sobre a distribuição do número de partículas (ou indivíduos) geradas ao longo da dinâmica e sobre a distribuição do tempo (ou geração) onde ocorre a eventual extinção do processo. Para provar estes resultados, a teoria de processos de ramificação faz uso das funções geradoras de probabilidade. Nós discutiremos estes resultados e os aplicaremos em um modelo simples de transmissão de informação.
Cristian Favio Colleti - UFABC (Santo André)
Nesta apresentação demonstramos a Lei Forte dos Grandes Números para a homologia persistente associada a uma classe de processos pontuais. Enunciamos também o Teorema do limite central. Esse é um trabalho em conjunto com Daniel Miranda (UFABC) e Rafael Polli Carneiro (UFABC).
Mario Estrada Lopez - Universidad Nacional da Colombia (Colombia)
Estudamos um sistema de partículas no grafo completo, no qual cada partícula é retirada após visitar um vértice e/ou acordar uma partícula dormente se o vértice contiver uma. Esta é uma variação do modelo conhecido como modelo dos sapos com tempo de vida não geométrico. Consideramos que o processo começa com uma partícula ativa em um único vértice. Mostramos que a proporção de vértices visitados e que o tempo de absorção do processo convergem em probabilidade para zero quando a quantidade de vértices no grafo completo tende para infinito.
Danilo Alvares - University of Cambridge (Reino Unido)
Análise de sobrevivência é um dos campos mais importantes na medicina, ciências biológicas e
engenharia. Além disso, os avanços computacionais nas últimas décadas têm favorecido o uso de
métodos Bayesianos neste contexto, fornecendo uma alternativa flexível e poderosa à tradicional
abordagem clássica. O objetivo deste minicurso é introduzir e implementar (em Stan) os mais
populares modelos de sobrevivência, tais como tempos de falha acelerado, riscos proporcionais,
riscos competitivos e modelos conjuntos de dados longitudinais e de sobrevivência. Códigos em
JAGS e INLA também serão disponibilizados.
Link para o
material do curso
For additional information, please contact us here. We will contact you back as soon as possible.
Deadline abstract submission: Jan 31st (Submission)
Notification of acceptance: Feb 9th
Deadline for early registration: Feb 12th
Workshop: Feb 21-23, 2024.
Undergraduate students: R$ 30,00
Graduate students: R$ 60,00
Others: R$ 120,00
Undergraduate students: R$ 40,00
Graduate students: R$ 80,00
Others: R$ 160,00
For lunch and dinner we recommend:
Registration and main activities : Auditório Luiz Antonio Favaro. Bloco
ICMC-4, 1º andar, sala 4-111.
Poster session : Hiperespaço Professor Loibel. Bloco ICMC-2, saguão térreo.
Reliability Analysis Special Session : Auditório Luiz Antonio Favaro. Bloco
ICMC-4, 1º andar, sala 4-111.
Probability Special Session : Bloco ICMC-5, sala 001.
For lodging and accommodations we recommend: Anacã São Carlos, Marklin Hotel & Suites and Sleep Inn
See below some information related to the previous editions of our workshop.
IX WPSM |
February 9-11, 2022, UFSCar | Book of Abstracts |
VIII WPSM |
February 12-14, 2020, UFSCar | Book of Abstracts |
VII WPSM |
February 13-15, 2019, UFSCar | Book of Abstracts |
VI WPSM |
February 5-7, 2018, UFSCar | Book of Abstracts |
V WPSM |
February 6-8, 2017, ICMC-USP | Book of Abstracts |
IV WPSM |
February 1-3, 2016, UFSCar | Book of Abstracts • Flyer |
III WPSM |
February 9-11, 2015, ICMC-USP | Book of Abstracts • Flyer |
II WPSM |
February 5-7, 2014, UFSCar | Book of Abstracts • Flyer |
WPSM |
January 28-30, 2013, ICMC-USP | Book of Abstracts |








Since the first edition (including the last edition number X) of the Workshop on Probabilistic and Statistical Methods, held in 2013, we have received the contribution of many colleagues and students.
If you have any question, please do not hesitate in contact us at wpsm.pipges@gmail.com.
{kind=link}
{kind=link}
{kind=link}