VIII Workshop on Probabilistic and Statistical Methods
February 12, 13, 14, 2020 - UFSCar - São Carlos - SP - Brazil
VIII Workshop on Probabilistic and Statistical Methods
February 12, 13, 14, 2020 -UFSCar - São Carlos - SP - Brazil
The Workshop on Probabilistic and Statistical Methods is a meeting organized by the Join Graduate Program in Statistics UFSCar/USP (PIPGEs) with the aim of discussing new developments in statistics, probability and their applications.
LOCATION:
12, 13 (full day) and 14/2 (morning only): Teatro Florestan Fernandes - next to BCO library at UFSCAR
Special Session in Machine Learning: Teatro Florestan Fernandes - next to BCO library
Special Session in Probability: Auditorio 3 - next to BCO library
See here the campus map for locations; look for 29 orange (Florestan)
Activities include invited speaker sessions, short talks, a poster session and a short course devoted to graduate students. The topics of this new edition include probability and stochastic processes, statistical inference, regression models, survival analysis and related topics.
Jorge Luís Bazan - ICMC-USP
Mariana Curi - ICMC-USP(Chair)
Rafael Izbicki - DEs-UFSCar(Chair)
Renato Jacob Gava - DEs-UFSCar
Vera Tomazella - DEs-UFSCar
Adriano Polpo de Campos - University of Western Australia
Carlos Alberto de Bragança Pereira - IME-USP
Francisco Louzada Neto - ICMC/USP
Mario de Castro - ICMC-USP
Osvaldo Anacleto - ICMC-USP
Vera Tomazella - UFSCar
Ana Carolina do Couto Andrade
Alex Leal Mota
Bruna Luiza de Faria Rezende
Caio Moura Quina
Camila Sgarioni Ozelame
Carlos Franklin Taco Pedraza
Djidenou Hans Amos Montcho
Gustavo Alexis Sabillón
Jessica Suzana Barragan Alves
Marcos Jardel Henriques
Marco Inacio
Marina Gandolfi
Milena Nascimento Lima
Naiara Caroline Aparecido dos Santos
Osafu Augustine Egbon
Patrícia Stülp
Renata Cristina Carregari

See below the titles and abstracts of the conferences and talks.
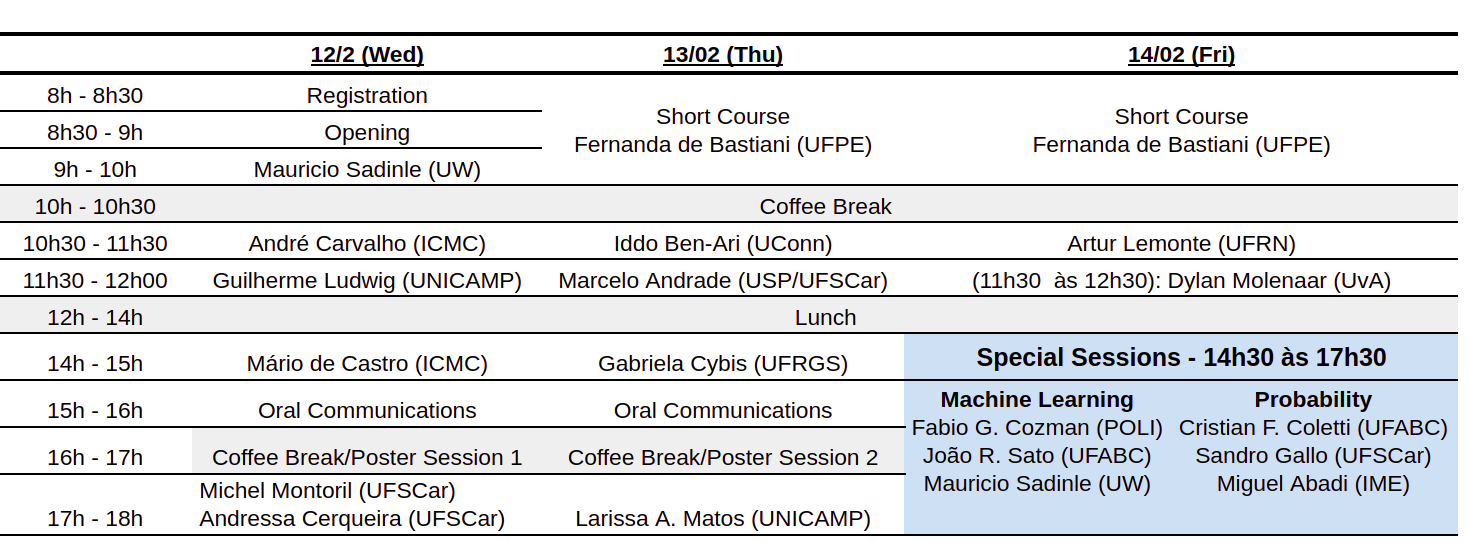
Click here to download the program of the meeting including titles and abstracts of all the presentations.
André Ponce de Leon F. de Carvalho, ICMC-USP
With to the recent expansion in data generation and the growing importance of exploring the knowledge contained in these data, Data Science is one of the fastest growing area of Exact Sciences. Large companies, like Amazon, Apple, Disney, Facebook, Google and Microsoft are hiring a large number of scientists, engineers and statisticians to work in this area. The ability to acquire, store and transmit data from the most diverse human activities, in the public and private sectors, has grown exponentially. This is generating massive volumes of data. These massive volumes of data, known as Big Data, come from a variety of sources and therefore have a wide variety of structures, ranging from traditional attribute-value tables to videos and messages on social networks. Analyzing these massive volumes of data can generate valuable information for decision making, enabling the extraction of new and useful knowledge. The difficulty of this analysis by traditional data analysis techniques has led to the development of new techniques, expanding the area of Data Science. This talk will present the main aspects, challenges and applications of Big Data and Data Science.
Artur Lemonte, UFRN
Os poderes locais dos testes da razão de verossimilhanças, Wald, escore de Rao e gradiente sob a presença de um vetor de parâmetros, ômega, que é ortogonal aos parâmetros restantes são considerados nesta apresentação. Será mostrado que alguns dos coeficientes que definem os poderes locais destes testes ficam inalterados independentemente se ômega é conhecido ou precisa ser estimado, enquanto que os outros coeficientes podem ser expressados como a soma de dois termos, o primeiro deles corresponde ao termo que é obtido como se ômega fosse conhecido, e o segundo, um termo adicional produzido pelo fato de ômega ser desconhecido. Esse resultado será aplicado na classe de modelos de regressão não lineares mistos e os poderes locais dos testes serão comparados.
Dylan Molenaar (University of Amsterdam)
Multi-group latent variable modeling approaches to study variability of measurement model parameters across categorical background variables like gender, cohort, and experimental conditions have been well established (e.g., Jöreskog, 1971; Meredith, 1993; Mellenbergh, 1989; Millsap, 2012). However, in many applications, the background variable is a continuous variable, for instance, age, socio economic status, or IQ. To study parameter variability in such cases, one can pragmatically choose to categorize the continuous background variable and apply a traditional multi-group model. However, this approach is suboptimal for various reasons. In the present talk, parametric and non-parametric alternatives to study parameter variability across continuous background variables are presented including moderated latent variable models, locally weighted latent variable models, and mixture factor models. The statistical properties of the models are studied, and the models are illustrated on real datasets. References: Jöreskog, K. G. (1971). Simultaneous factor analysis in several populations. Psychometrika, 36, 409- 426 Meredith, W. (1993). Measurement invariance, factor analysis and factorial invariance. Psychometrika, 58(4), 525-543. Mellenbergh, G. J. (1989). Item bias and item response theory. International journal of educational research, 13(2), 127-143. Millsap, R. E. (2012). Statistical approaches to measurement invariance. Routledge.
Gabriela Cybis, UFRGS
High dimension small sample size datasets are common in fields like genetics, biological imaging and econometrics. These datasets present a significant challenge for statistical testing in clustering problems. We present a nonparametric U-statistic based approach for clustering and classification tailored for these types of problems. The methods require few assumptions about the data generating processes and have more statistical power than competing alternatives. We also present the r-package Uclust for clustering and classification under this framework. To showcase the methods, we present an application to classifying ECG data based frequency spectrums, and an application to hand movement classification based on a concept of the union of homogeneous subgroups.
Ido Ben-Ari (University of Connecticut)
Random population dynamics with catastrophes (events pertaining to possible elimination of a large portion of the population) has a long history in the mathematical literature. In this paper we study an ergodic model for random population dynamics with linear growth and binomial catastrophes: in a catastrophe, each individual survives with some fixed probability, independently of the rest. Through a coupling construction, we obtain sharp two-sided bounds for the rate of convergence to stationarity which are applied to show that the model exhibits a cutoff phenomenon.
Larissa Avila Matos, UNICAMP
A semiparametric mixed-effects model for censored longitudinal data In longitudinal studies involving laboratory-based outcomes, repeated measurements can be censored due to assay detection limits. Linear mixed-effects (LME) models are a powerful tool to model the relationship between a response variable and covariates in longitudinal studies. However, the linear parametric form of LME models is often too restrictive to characterize the complex relationship between a response variable and covariates. More general and robust modeling tools, such as nonparametric and semiparametric regression models, have become increasingly popular in the last decade. In this article, we use semiparametric mixed models to analyze censored longitudinal data with irregularly observed repeated measures. The proposed model extends the censored LME model and provides more flexible modeling schemes by allowing the time effect to vary nonparametrically over time. We develop an EM algorithm for maximum penalized likelihood (MPL) estimation of model parameters and the nonparametric component. Further, as a byproduct of the EM algorithm, the smoothing parameter is estimated using a modified LME model, which is faster than alternative methods such as the restricted maximum likelihood (REML) approach. Finally, the performance of the proposed approaches is evaluated through extensive simulation studies as well as applications to datasets from AIDS studies.
Mário de Castro, ICMC-USP
Generalized fiducial inference for the precision of a measuring instrument without available replications on the observations is our main interest. In this talk, we discuss two new estimation procedures for the precision parameters and the product variability under the Grubbs model considering the two-instrument case. One method is based on a fiducial generalized pivotal quantity and the other one is built on the method of the generalized fiducial distribution. The behavior of the point and interval estimators is assessed numerically through Monte Carlo simulation studies. The methodology is applied in the analysis of a data set from a methods comparison study. This is joint work with Lorena C. Tomaya (UFAC).
Nonparametric Identified Methods to Handle Nonignorable Missing Data
There has recently been a lot of interest in developing approaches to handle missing data that go beyond the traditional assumptions of the missing data being missing at random and the nonresponse mechanism being ignorable. Of particular interest are approaches that have the property of being nonparametric identified, because these approaches do not impose parametric restrictions on the observed-data distribution (what we can estimate from the observed data) while allowing estimation under a full-data distribution. When comparing inferences obtained from different nonparametric identified approaches, we can be sure that any discrepancies are the result of the different identifying assumptions imposed on the parts of the full-data distribution that cannot be estimated from the observed data, and consequently these approaches are especially useful for sensitivity analyses. In this talk I will present some recent developments in this area of research and discuss current challenges.
Learning communities in weighted networks
Network models have received an increasing attention from the statistical community, in particular in the context of analyzing and describing the interactions of complex random systems. In this context, community structures can be observed in many networks where the nodes are clustered in groups with the same connection patterns. In this talk, we will address the community detection problem for weighted networks in the case where, conditionally on the node labels, the edge weights are drawn independently from a Gaussian random variable with mean and variance depending on the community labels of the edge endpoints. We will present a fast and tractable EM algorithm to recover the community labels that achieves the optimal error rate.
Scalable modeling of nonstationary covariance functions with regularized B-spline deformations
We propose a semiparametric method for nonstationary covariance function modeling, based on the spatial deformation method of Sampson and Guttorp (1992), but using a low-rank, scalable, regularized deformation function. We show that fine tuning of the regularization parameters can ensure that the deformation does not fold in on itself, and therefore yields proper covariance function estimates. An application to rainfall data illustrates the method.
Um método de busca de matriz Q em modelos da TRI multidimensionais
Recentemente, a matriz Q, que é um elemento responsável por captar a relação entre itens e traços latentes e está presente na grande maioria dos modelos de diagnóstico cognitivo (MDC), foi incorporada na formulação dos modelos da teoria da resposta ao item multidimensionais (TRIM). Na prática, para utilizar um modelo com matriz Q, seja ele um MDC ou um modelo da TRIM, é necessário primeiro estabelecer a relação entre itens e traços latentes construindo uma matriz Q apropriada. Embora este processo de construção da matriz Q seja tipicamente feita por especialistas no tema dos itens, ele é um processo subjetivo e, portanto, pode implicar em equívocos, resultando em importantes problemas práticos, como, por exemplo, influenciar a estimação dos parâmetros do modelo. Neste trabalho, propomos um método de busca de matriz Q em modelos da TRIM baseado em critérios projetados para fornecer informação máxima sobre alguma propriedade de interesse. Para isso, utilizamos o algoritmo de troca, um método eficiente e sistemático para a busca de matrizes, visando encontrar uma matriz Q que maximize alguma propriedade de interesse. Além disso, o método fornece informações de eficiência que podem ser úteis na reavaliação de uma matriz Q. Um estudo de simulação foi realizado para analisar o desempenho do método proposto utilizando dois diferentes cenários construídos a partir da variação do número de itens e do número de dimensões do traço latente. Para ilustrar o uso do método de busca de matriz Q em dados reais, utilizamos um conjunto de dados com respostas de 1.111 estudantes a uma versão do BDI com 21 itens.
Wavelet denoising of broadband pulsed signals via empirical Bayes thresholding
Cetacean bioacoustic research is rapidly increasing in importance to answer questions related to the human contribution on acoustic environmental changes. Acoustic towed array is a technique using sometimes opportunistic research vessel platforms in collaboration with other oceanographic investigations. This situation generates additional noise sources that affect or partially mask the signal of interest. This compromises the correct detection and possible classification of the species. In this work, combined wavelets and empirical Bayes thresholding are used to denoise the audio recording of odontocetes echolocation clicks. This method was able to denoise clicks without affecting their features.
Distributional regression approach using GAMLSS
The generalized additive models for location, scale and shape, GAMLSS, are univariate distributional regression models, where all the parameters of the assumed distribution for the res- ponse variable can be modelled as additive functions of the explanatory variables. GAMLSS address the problem of choosing an appropriate distribution for the response variable, and models how the distribution parameters vary with changes in the explanatory variables. GAMLSS, its statistical modelling philosophy and its implementation in the software R will be introduced. The different distributions for modelling the response variable, and their properties will be described. These dis- tributions include continuous (positively or negatively skewed and with high or low kurtosis), discrete and mixed distributions. Different additive terms for modelling the parameters of the distribution such as linear, non-parametric smoothing and random effects terms will be shown. Also different modelling selection techniques and diagnostics for checking the model adequacy will be addressed. All example given are real data examples.
Machine Learning, coordinated by Rafael Stern, DEs - UFSCar
Explaining Machine Learning
There is now wide interest in techniques that explain automatic decisions generated through machine learning. And there are several ways to generate such interpretations and to explain what happens inside a machine learning "black-box" such as a large random forest or a deep neural network. This talk will discuss various perspectives on how best to explain machine learning techniques, focusing both on textual explanations and on explanations for large-scale embeddings.
Applications of Computational Statistics and Machine Learning in Brain Imaging Data
In this presentation, we will introduce how computational statistics and machine learning methods can be useful to analyze brain imaging data. This is an interdisciplinary research which requires state-of-the-art knowledge from both Neuroscience and machine learning to be successful. Brain imaging data will be introduced to the audience, with the main concern on data structure and quantitative features. Moreover, the mindset of how this combination may be approached in order to raise new questions will be discussed. The presentation will also focus on illustrations of these applications in neurodevelopment, brain disorders, brain-computer interfaces, and Education. Finally, the main challenges and perspectives will be discussed.
Least Ambiguous Set-Valued Classifiers with Bounded Error Levels
In most classification tasks there are observations that are ambiguous and therefore difficult to correctly label. Set-valued classifiers output sets of plausible labels rather than a single label, thereby giving a more appropriate and informative treatment to the labeling of ambiguous instances. We introduce a framework for multiclass set-valued classification, where the classifiers guarantee user-defined levels of coverage or confidence (the probability that the true label is contained in the set) while minimizing the ambiguity (the expected size of the output). We first derive oracle classifiers assuming the true distribution to be known. We show that the oracle classifiers are obtained from level sets of the functions that define the conditional probability of each class. Then we develop estimators with good asymptotic and finite sample properties. The proposed estimators build on existing single-label classifiers. The optimal classifier can sometimes output the empty set, but we provide two solutions to fix this issue that are suitable for various practical needs.
Probability, coordinated by Renato Gava, DEs - UFSCar:
Convergence to a transformation of the Brownian Web for a family of Poissonian trees
We introduce a system of one-dimensional coalescing random paths starting at the space-time points of a homogeneous Poisson point process in $\mathbb{R} \times \{0\}$ which are constructed as a function of a family $(\Lambda_n)_{n \in \mathbb{N}}$ of Poisson point processes. We show that under diffusive scaling this system converges in distribution to a continuous mapping of the Brownian Web. Joint work with Leon A. Valencia Henao (UdeA, Colombia).
Variations on Kac's Theme
We presented several variations to the well known Kac’s Lemma which are useful to compute size of clustering phenomena that apply still just under stationarity and ergodicity.
For additional information, please contact us here. We will contact you back as soon as possible.
Deadline abstract submission: Jan 18th (Submission)
Notification of acceptance: Jan 28th
Deadline for early registration: Feb 1st
Click here for more information (Restaurants)
Researchers/others: R$ 80,00
Graduate students: R$ 55,00
Undergraduate students: R$ 30,00
12, 13 and 14/2 morning: Teatro Florestan Fernandes - next to BCO library
Special Session in Machine Learning: Teatro Florestan Fernandes - next to BCO library
Special Session in Probability: Auditorio 3 - next to BCO library
See here the campus map for locations; look for 29 orange (Florestan)
For lodging and accommodations we recommend Anacã São Carlos
See below some information related to the previous editions of our meeting.
6, 7, 8 February 2018, ICMC-USP
Book of Abstracts •
1, 2, 3 February 2016, UFSCar
Book of Abstracts • Poster
9, 10, 11 February 2015, ICMC-USP
Book of Abstracts • Poster
5, 6, 7 February 2014, UFSCar
Book of Abstracts • Poster
 | 
|
 |
 |
 |
 |
 |
Since the first edition of the Workshop on Probabilistic and Statistical Methods, held in 2013, we have received the contribution of many colleagues and students.
If you have any question, please do not hesitate in contact us at wpsm.pipges@gmail.com! We are looking forward to seeing you in São Carlos.
{kind=link}
{kind=link}
{kind=link}